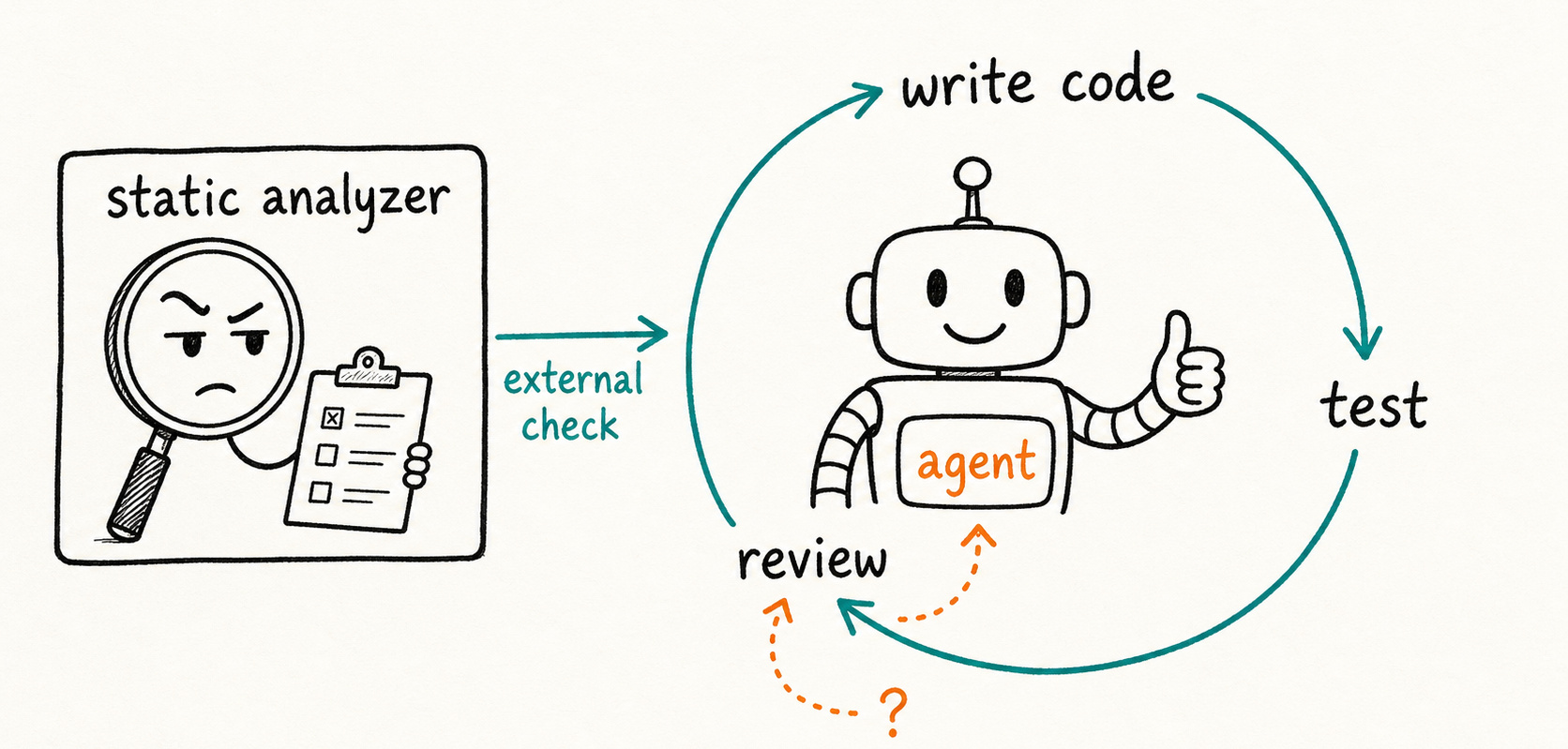
A coding agent that reviews its own output carries the same blind spots into the review that produced the bugs in the first place. That is not verification: it is the same bias running twice. A static analyzer breaks that loop. It runs locally and cannot hallucinate a finding. Moving it from CI into the agent’s turn is the whole upgrade.
Andrej Karpathy drew the line crisply at Sequoia Ascent 2026: vibe coding (writing by feel, letting the model handle correctness) raises the floor, agentic engineering (autonomous loops acting on your codebase) raises the ceiling. Where that ceiling lands depends entirely on what your agent gets checked against.
The whole thing with agentic loops happened so quickly, that most “AI assisted teams” don’t have a proper verification process yet that can keep up with the speed at which agents are writing code. Reviews are the new bottleneck: Faros reports that teams with high AI adoption merge 98% more pull requests, while PR review time grows by 91%. The obvious fix is to ask the agent to test its own work.
But that is not a good fix. Not currently, and very likely not even in the future.
Try a quick experiment. Take any non-trivial change your agent just produced and ask it: “are you sure?” In my experience it will rewrite, then agree with you, then agree with the opposite if you push (try it: takes under two minutes). Confidence is cheap, as I argued in GenAI vs Static Analysis. What it does not produce is a deterministic, objective check.
Why the agent cannot verify its own work
Start with something most users have not considered. LLMs are trained to satisfy the user, a property known as sycophancy, and that backfires in code review. The model reads the implicit expectation behind your question and reacts to that. Ask with a tone that implies concern and it finds problems. Ask with a tone that implies confidence and it validates. Same code, different output, depending entirely on how the question was framed.
This looks like confirmation bias, but strictly speaking, it’s not. The mechanism is baked into the training, not the cognition. The practical result, however, is identical.
Second, we also tend to trust confident sources, and LLM are good at sounding plausible and confident. In my experience, models have grown more confident over time. I ran the same code-review experiment in 2023 and again in 2025. The 2023 model was hesitant and easy to flip. The 2025 model is always confident, often stubborn, and just as wrong. It has not learned to be right; it has learned to sound right.
Third, and most fundamentally: the agent has no external ground truth. Its sense of “correct” is statistical, drawn from training data where bugs and fixes sit side by side. There is no specification it can consult, no oracle, no simulator running in its head. When it reviews its own code, the reviewer is the writer, drawing from the same distribution and sharing the same blind spots. This is structural. No amount of scale, prompting, or fine-tuning fixes it on its own.
LLMs try to please you, sound confident even when wrong, and have no external ground truth to verify themselves against.
But I ask my agent to write tests
Good try. And of course it does. But those tests reflect what the agent thought the code should do. Same prompt, same misreading, same missed edge case.
I have found it helps to clear the context before running tests, or to use a different model. But in the end, it is just a test. Tests only cover the inputs someone thought to try, as I discussed in static vs dynamic analysis.

The other obvious question is: Are the tests worth any money? We all know that it’s hard to write meaningful tests, and how easy it is to be biased. At least a review is in order, which means we are back to square one.
The numbers from outside the lab are not flattering. Veracode’s 2025 GenAI security report tested more than 100 LLMs on 80 coding tasks: 45% of generated code contains security flaws.
If your agent only checks its own work against its own tests, you lack an independent ground truth.
What a static analyzer brings to the loop
A first step out of that dilemma is to add a static analyzer as an external ground truth inside the agentic loop. Not after the pull request, but inside the agent’s turn, so the agent can act on the findings before the code goes anywhere.
If you have read earlier posts in this series, you already know what a static analyzer is and how it works. What matters here is what it brings that the agent cannot provide itself: It is an automatic, unbiased assessor that does not require inputs (unlike dynamic testing). That means regardless of what the agent’s goal is, it will just run the checks without any expectations, and report the findings.
It also brings determinism. The rules are fixed before the analysis runs and do not shift based on how the question is framed. The analyzer does not negotiate. It produces the same output whether the agent is confident, hesitant, or hallucinating.
The third difference is coverage. Pattern-based linters miss semantic and business-logic issues, but catch the structural and syntactic patterns the model’s training glosses over. A second LLM review pass shares the same distribution and the same sycophancy: what the first pass missed, the second misses too. Together, an agent and a static analyzer cover more ground than either does alone. And unlike an extra API call, running a local analyzer carries no per-check cost.
A static analyzer does not share the agent’s blind spots. It also cannot be talked out of a finding.
The loop already works, modestly
This is not a thought experiment. Blyth et al. wrapped GPT-4o with Bandit and Pylint as an iterative feedback loop on the PythonSecurityEval benchmark. Within ten iterations, security issues dropped from over 40% to 13%, readability violations from over 80% to 11%, and reliability warnings from over 50% to 11%. Just two mature analyzers, plugged into the inner loop.
I have seen this myself as well. The agent reads a static analysis finding, understands the issue in context, and often fixes it correctly on the first attempt. And the other direction works too: the analyzer gives the agent a tighter feedback loop than a failing test does, because it reports the structural problem rather than just a symptom. One plus one gives you three here.
Many teams already have a Static Analysis tool sitting in CI. The tool is not the upgrade: moving it is. A finding after the pull request is a report for a human to read; the same finding inside the agent’s turn is a signal the agent can act on immediately, before the code is even committed. That shift, from report to signal, is the whole argument in practice.
Keep the CI checks too. They are the safety net against the “works for me” argument, now coming from robots, and the right place for deep analysis comparing against the prior state to catch new issues. An LLM cannot do that gating job: run it twice, get two finding lists, and the gate becomes a coin flip. Setting temperature to zero stabilizes the output but kills the qualitative behavior that made the model useful for review.
Limits of Static Analysis, and what is still unsolved
Static analysis sees implementation bugs in your code, but it does not know whether the code does the right thing. If you asked the agent for a sorting algorithm and it hardcoded the answer instead, the linter will pass it without comment. The specification gap is real, and no tool in this loop closes it.
That said, looking back at my own post from last year, which feels like a different lifetime and is still valid, I have hope. Agents and static analysis are complementary, and we can let the agent do the parts where SCA is weak. We already see it happening: agents explain findings more clearly than the analyzer does, and agents are starting to write loop invariants for formal verifiers.
The agent is good at proposing. The analyzer is good at checking. Put each where it belongs.
Do’s and Don’ts
Let’s start with what we have today. A short field guide to using Static Analysis with agentic workflows:
- ✅ Do move the analyzer from CI into the agent’s loop. Feedback that arrives after the pull request is a report. Feedback that arrives during the agent’s turn is a signal it can act on.
- ✅ Do treat the warning count as a signal in itself. A clean report achieved in one shot is suspicious: the agent may have suppressed findings rather than fixed them, or found a way to trick the analyzer. Expect an honest first run to start noisy and converge over iterations.
- ✅ Do keep the human in the loop for “is this the right thing to build.” The analyzer cannot answer that.
- ⚠️ Don’t let the agent suppress findings it cannot explain. The right path is to address the root cause, not silence the signal. This is exactly the failure mode I described in stupid false positives and error absorption, just happening faster.
- ⚠️ Don’t mistake a clean linter report for a correct program. A passing static check means the code satisfies a set of rules. It does not mean the code is right.
Summary
The cheapest correction is also the oldest one: add a static analyzer in the inner loop, doing the independent and deterministic job the agent cannot do for itself. It will not catch everything. It will catch a lot, and it will catch a different lot than the agent’s own tests do. That is the point.
At this point, doing nothing will create exponentially more problems in the future. But adding SCA to the loop could be the step towards multiplied success. DORA’s 2025 report is blunt that AI amplifies the system you already have, weak spots included. That would be a perfect “technical debt generator”.
What’s next?
How does your agent’s behavior change when you add Static Analysis to the loop.