Adding a static analyzer to your coding agent’s loop changes how the agent behaves. Besides catching bugs, you can see that the token bill shifts, the agent is more focused, and it reduces code bloat. By the end of this post, you will understand all three shifts, know how to design the integration that delivers them, and why a low-false-positive analyzer pays off three times.
My previous post explained why agents cannot verify their own work reliably and why a static analyzer brings determinism they cannot fake. This post is about what happens next.
When I added a static analyzer to my own agent setup, I was first impressed by the quality boost. It found more bugs, and that’s exactly what I wanted. But it also had unforeseen side effects. I believe the real value of Static Analysis in the agent loop is not just about fewer defects, but also about how it changes the agent’s behavior for the better.
Change 1: The token bill goes up – but it’s good
Adding Static Analysis to an agentic loop uses more tokens than running without one. The reason is structural, as I discussed in my previous post. The agent can now see its own mistakes and has to do corrective work it would not have done otherwise, which means extra iterations and more tokens consumed.
If you want data, here is a well-done recent study by Concordia University (Tokenomics), which found that iterative code review accounts for 59.4% of all token consumption in agentic coding tasks. It is the single dominating cost driver.
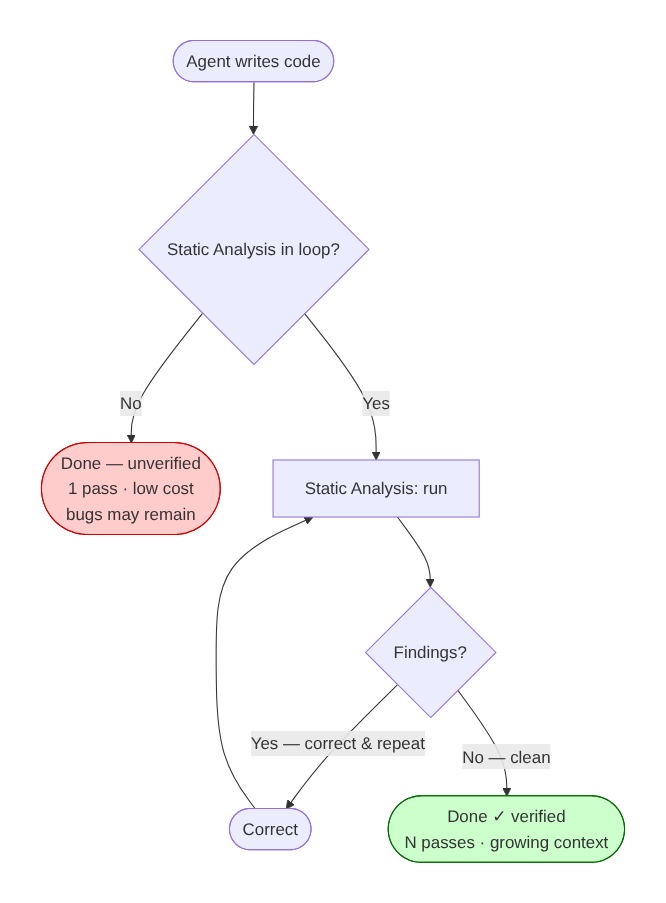
So the cost is real but this is what we want. Consider what happens when an agent declares “done” after one pass with no external check. Fewer tokens, sure, but wrong code. That is not a saving but a deferred cost with interest. Even worse, some research on LLM self-correction suggests that without external feedback, iterative self-correction does not merely stall but can actively degrade performance.
This increased token usage is just the usual “shift left” by a different name. Every token the agent spends iterating on a finding is a token spent during development rather than during QA, integration testing, or a production incident. The iteration bill is real, but the bill for letting bugs through would be higher.
Skipping verification does not save cost; it moves the bill to a later, more expensive stage.
Change 2: The agent reads less
Think of the agent as a driver in an unfamiliar city. Without a GPS, it reads everything before each move: entire files, full function bodies, surrounding context, just in case something matters. It is expensive, and the agent often changes things it was not sure about, just to cover its bets.
A static analyzer that says “line 47, null pointer dereference” is the GPS. The agent does not read the file. It jumps to line 47, reads the ten lines around it, fixes what the tool flagged, and moves on. The map is irrelevant. The turn instruction is everything.
Researchers call this cognitive offloading: delegating the “where is the problem?” question to an external tool so the agent can focus entirely on “how do I fix it?” GitHub’s analysis of agentic workflows confirms that agents who receive targeted, scoped context use fewer tokens per task than those loading entire files before acting.
Of course, a GPS can be wrong. Static analyzers produce the same kind of misdirection through false positives, and the noisier the tool, the more recalculating the agent must do. The limit is real but does not invalidate the approach.
Static Analysis tells the agent exactly where to look, eliminating the full-file scan before every fix.
Change 3: The code changes get smaller
Putting Static Analysis in the agentic loop results in smaller code changes. GitHub’s analysis of agentic workflows confirms it, too: agents who receive targeted, scoped context produce more focused changes than those loading entire files before acting. The scoped input produces a scoped output.
The mechanism is uncertainty. When an agent reads the whole file and is still not sure what is wrong, it tends to hedge. It refactors the surrounding function, adds guards everywhere, and restructures “just to be safe.” Each of those changes is code that was not asked for, may introduce new issues, and will need a human to review it. This is code bloat: not lines added to fix the bug, but lines added to cover the uncertainty.
Back to our analogy: The GPS does not reroute your entire trip when you miss a turn. It corrects the next step, nothing more. An agent with a static analyzer works the same way, receiving “line 47,” fixing it, and stopping.
One caveat is that the agent now only checks what the tool flags. False negatives, i.e., real bugs Static Analysis doesn’t catch, are the other side of this precision coin. That gap deserves its own post.
Precise findings produce precise fixes, while vague signals produce larger rewrites.
The MCP and skills escape hatch
All three shifts above happen regardless of how you wire Static Analysis into the loop. But one needs to be controlled, and that is the token cost. The key is MCP (Model Context Protocol), which is the interface that lets coding agents call external tools, including static analyzers, and receive structured results back.
As the Concordia study finds, most of the review cost comes from input tokens. With Static Analysis in the loop, at least the agent doesn’t need to read the full files itself, which already saves a lot of tokens. Still, the specific integration matters a lot. Dumping the full analyzer report into the agent’s context as a block of text (rule names, file paths, line numbers, messages, and a long preamble) wastes money and clutters the context window.
A well-designed MCP server exposes Static Analysis results as structured tool output: a compact list of findings, each with a file name, a line number, and a short description. The output contains no boilerplate, no repeated headers, and no prose around the data. Practitioners using minimal MCP schemas and just-in-time tool loading have measured input token reductions above 96% for similar tasks. The analyzer result becomes a signal, not a document.
Skills offer a second reduction, but different in kind. Where MCP controls what the tool outputs, a skill prescribes the process the agent follows. Without one, the agent spends tokens exploring how to run the analysis: which files to check, which tool to invoke, and in what order. A skill encodes that process once. The agent executes rather than searches, and the exploratory overhead disappears, too.
Iterations drive cost, but compact MCP output and predefined skills both reduce what each iteration actually spends.
Summary
Static Analysis in the agentic loop costs more tokens than a bare agent run, but those extra tokens fix bugs before they reach code review or production. Naive integration amplifies the cost through bloated context; a well-designed MCP server keeps it in check by sending compact, structured findings,rather than a prose report. From there, the agent reads less, fixes precisely what it is told, and leaves a smaller diff for you to review.
If you are adding Static Analysis to an agent today, look at the quality gain and not just token usage. And, perhaps the most important factor, pick an analyzer with a low false-positive rate. All three behavioral changes depend on signal quality. A high-false-positive analyzer does not reduce token cost or code bloat; it amplifies both.
What’s next?
Bugs that are found late, are 100x more costly to fix.