The idea of Static Analysis sounds simple: Read the code, check each line, and report the bad stuff. However, it is far from easy. In this article, we look at the challenges that it has to overcome, and dive a little bit into the theory. You will see that it is much more than just pattern matching, and learn what you should avoid to get better results.
As I said earlier, this is not a research blog. Yet, I owe you a simple explanation how Static Analysis works, and that will require a little bit of terminology. While this article won’t be detailed enough to build your own tool, it will give you enough intuition to understand your tools better. But be warned, this article has a bit of theory. If you just want the conclusions or a very quick summary, you can limit your reading to the blue boxes.
A (really) short history of Static Analysis
To get started, I briefly thought about presenting you the history of Static Analysis. But then I decided that this would not be useful for you, and also take me too much time. Hence, here are my only two sentences about the origins of Static Analysis: It probably started in the 1970s at Bell Labs, where Stephen C. Johnson created a tool he named “lint” to check for portability issues in C programs. Today, about 50 years later, we have no shortage of methods and tools, and we use it to verify all kinds of properties.
Our goal: Find specific bugs in a specific program
To learn about the challenges, I brought a code example that we will try to understand:
function foo (value: Integer) return Integer is
res : Integer := 0;
begin
for i in 0 .. 100 loop
if random() > 10 then
res := res + 1000;
end if;
end loop;
if 42 = value then
shutdown(value);
end if;
return res;
end foo;(Yes, this looks a bit like Ada.)
In an earlier post we have already discussed that Static Analysis cannot tell whether this program is correct, since it doesn’t know the intentions of the author. (In fact, even the author, which is me, doesn’t know the purpose in this case). Instead, Static Analysis can only check for specific types of bugs. So let’s assume we want to check for the following (formally called “properties” or “verification conditions”):
- Is the function “shutdown” ever called?
- Can my program return negative values?
There are many other questions that we can ask. And in fact, many questions are so generic, that Static Analysis will automatically answer them for every program that you give to it. For example: Do I get divisions by zero, am I trying to write an array beyond its bound, are there race conditions in my program…
To answer all of these questions, we need to do solve a number of problems.
Challenge #1: Reading the Code and its Structure
This seems trivial for a human, but remember, we are writing a program that analyzes another program. Hence, we need to tell our program how to read the code of a specific programming language.
What does it mean to “read” a code? In essence, it’s about identifying the structure and extracting the data, so that we can do something with it. The structure is defined by the rules the programming language that we are analyzing, formally called “grammar”.
Parsing typically involves two steps:
- Lexical analysis: Splitting the code into a sequence of words (”tokens”). This is a little bit how us humans are reading text. We first need the word boundaries, otherwise it becomes really messy (although human reading perception is actually much more complex, as described here). More specifically, each token is a basic unit of the language, e.g., “if”, and “=” and our variable name “res”. During tokenization, we already can find typos such as “reutrn” or quotes in the wrong place.
- Pre-processing: If your language has macros, these are resolved now, as textual replacements. Interesting to know: This is before the grammar is checked. In other words, the pre-processor has no understanding of the language.
- Parsing: Checking that the pre-processed words are in the right place and have meaning according to the grammatical rules. This is the actual parser and it does the heavy lifting. Again comparing it to natural language, the parser would tell you that the sequence “I really need a coffee now” makes sense, but the sequence “now a need coffee really I” does not. With that in mind, perhaps Yoda doesn’t need to visit a grammar school, but just switch his parser.
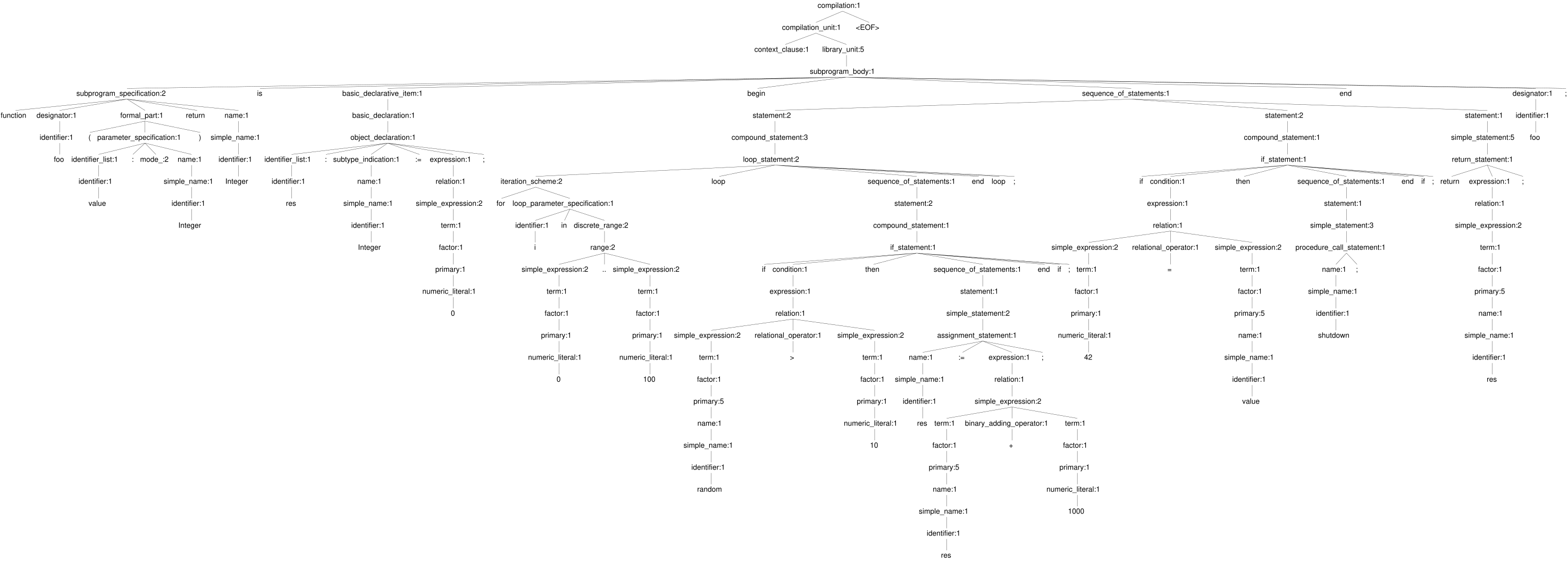
At the end of this step, we have an internal representation of the source code like shown in the picture above. This is already useful to tell if something is fundamentally wrong. For example, we can easily spot if someone tried to declare a variable in an invalid place, our misspelled “Ingteger”. A good portion of coding guidelines be addressed with this information, and a good part of compiler errors can be predicted like this. Last but not least, we can already “mark” all the standard questions in that internal representation, so that we can answer them later.
Checking syntax errors is included in the first step of static analysis.
As stereotypical computer scientist, of course I have created my own programming language and parser. While it will definitely not help making friends, it is very useful to understand how grammars work. If you are interested, here is a starting point that I would count as “learning by doing”, instead of suffocating in theory.
Challenge #2: Data and Control Flow Analysis
Now that we have parsed the code, we can go line by line and understand the the program and its variables and execution flow. This is arguably the most important task for Static Analysis tools, which separates the wheat from the chaff.
To find out which control flows are possible, we have to know the values at each control decision. For example:
if 42 == value then
shutdown(value);
end;We can only know whether the if-condition is entered and shutdown() was called, if we know what’s stored in “value”. And to know that, we have to:
- Find out that “value” it is a function input and
- Track each modification that may have happened before its use in this if-statement.
This is known as data flow analysis.
One complication (and actually the norm) is, that values can have a reverse dependency on control decisions. In our code we can see that “res” depends on the surrounding if-statement. Hence, data and control flow analysis must go hand in hand, statement by statement. It doesn’t make much sense to ignore one of them, since the analysis would be terribly imprecise.
Another complication: We don’t just simulate one specific input, but we want to analyze all possibilities. Therefore, Static Analysis must have a way to store ranges (or more generally, sets) of values. And moreover, it must know what happens to these sets whenever the variable is modified, e.g.:
-- here res could be between -10 and 10
res := res + 1000;
-- now res could be between 990 and 1010Hence, each operation will be represented as a set of possibilities. This is known as value analysis.
With data and control flow analysis, we can not only answer all the standard questions mentioned in the beginning (overflows, termination etc), but also try to answer the specific questions whether “shutdown()” was called. Here it is clear. Even baby Yoda can deduce that it is called when value=42, since it is written in the code (see also Defensive Coding). However, we don’t know whether this condition occurs. We have no information about “value” itself, hence we cannot definitely answer with a yes or a no. Without further information about “value” – maybe from the caller of foo() – we have to live with this uncertainty.
If you have a static analysis tool that wants to be on the safe side, it would reply with “yes, shutdown() is possibly called”. On the other hand, if you have a tool that wants to minimize the warnings, it would report nothing. Some people think that the former case is a False Positive, but if you think about it, it isn’t. Our analysis is simply lacking context.
Now let’s get to the question if our program can return negative values. Unfortunately, there is no certain answer here. In our code, the value of “res” essentially depends on a call to random(), which by definition cannot be predicted. In that case, whatever we do, even providing call context, won’t give us a better answer. This property remains uncertain.
Control and data flow analysis is key. If you want more precise analysis, you can provide information about possible values of input ranges. But it may not always help.
Challenge #3: Alias a.k.a. Pointers and References, and dynamic memory
Now let’s add more complications that would even give senior Yoda severe headache: Pointers and dynamic memory. Whoever invented those, was both a genius and an evil person (probably John von Neumann). Those are very complicated to analyze, because references or pointers refer to an object under different names.
To still do our value analysis, we need to decode where references are pointers are going, and make sure we forward every modification to every other pointer that refers to the same location. This is a bit like playing Scavenger hunt: You are following and decoding one hint after another, until you finally arrive at the prize. Or you may get lost somewhere in between, because the clue was too vague.

The technique of solving this is known as Alias Analysis or Points-To-Analysis, and it is extremely hard, because:
- Pointers can change: A pointer can start pointing to one variable, then later point to another.
- Pointers can point to other pointers: Instead of pointing to a value, a pointer might point to another pointer, making it more complex to track.
- Dynamic memory allocation: When memory is allocated dynamically (
mallocin C,newin C++), the address isn’t known until runtime, making static analysis difficult. - Aliasing: Two different pointers might point to the same memory location, so changing one affects the other.
Pointers are the enemy of Static Analysis, since in principle, they can change all parts of a program from everywhere. And just like a Scavenger hunt, they take a long time.
Minimize use of pointers and references, to get faster and more precise analysis results.
Challenge #4: Interprocedural Analysis and Context Sensitivity
So far we have only discussed how to analyze a single function. But we developers use functions/procedures/methods to manage complexity. How does it work then? The answer is interprocedural analysis.
We first have to build a call tree. For that, we can use our parser information to identify which function calls which. The call tree for our code is simple:
foo
├── random
└── shutdownWe can also see from it, that foo has no callers, hence foo could be the entry and the starting point of the analysis.
Now again, comes a tricky bit. Function calls can be difficult to predict when:
- There are function pointers – To see which function will be called, we again need value analysis. This is another henn-egg problem, like we have seen before with data- and control flow analysis.
- There is polymorphism. You have to know which “variant” of the object you have, when it is called. This requires a precise tracking of data and control flows, otherwise you have to consider many different variants at each call, losing precision exponentially.
- Functions call themselves, directly or indirectly (”recursion”). We have to figure out how deep this can go.
Let’s assume we solve that, too. After knowing who calls whom, we can run our data- and control flow analysis across function borders. When we encounter a function call, we can hand over the computed value sets of the inputs and analyze the called functions more precisely. At the end of the function, we take the computed value sets for the outputs, and copy them back to the caller.
All of that can get nasty and require things like fix-point iterations.
Now to the final interprocedural challenge: Because functions are re-usable mini-programs, they are often called from more than one location, with different inputs. Let’s assume our function foo() would have two callers, one that calls with input 42, and another one calling with inputs between 0 and 13. If we want to be precise in our analysis, we have to analyze the function foo() twice, since in both cases the result will be totally different.
Function pointers, polymorphism and recursions add uncertainty to Static Analysis, and slow it down. Avoid if possible.
Even more challenges…
If you are still here, then you seem to love problems. Or perhaps you are Yoda, in that case, apologies. Good news, there are more challenges which we don’t discuss today, for example loops, concurrency, target/compiler specifics, and side effects of functions and expressions. I will have to put you off for another article, because each of them is complex enough to fill a book.
Putting it all together
This is the point where I take all of the things above and show you how to combine them to build a full Static Analysis tool.
Except I won’t, sorry.

As so often in life, there is more than one solution. In fact, each of the problems described above has multiple solution approaches. Which one you choose, depends on how rigorous you want to be, and what types of bugs you want to find.
For example, you could decide to skip Alias Analysis entirely, if you won’t analyze programs with pointers. Or you could achieve Value Analysis by translating each operation to a mathematical equation in static single assignment form and throw it into a linear solver. Or you could feed your whole code to GenAI, which does all of these things implicitly and behaves like a stochastic parrot telling you what it has heard from other people who had similar code – I will definitely write about that soon.
For now, here are a few popular and proven approaches to Static Analysis:
- AST Matching: These approaches are heavily parser-based, i.e., stopping after step 1 and using heuristics to spot bad patterns. They are often called linters. It is easy to write new rules, but the analysis is pretty much agnostic to data and control flows. This is good if you are interested in ultra fast performance.
- Abstract Interpretation: This is a mathematical approach based on set theory and fix-point iterations, which is typically trying to consider a superset of all possibilities. The focus here is on never missing any possibility, at the cost of False Positives. For example, if unsure whether a variable can be negative, it will assume it can, so that we are on the safe side. This is good if you are interested in safety, security and robustness.
- Theorem Proving: Another mathematical framework that translates the program into theorems and lemmas. This often involves a form of reverse computation (Hoare Logic) to determine which inputs would be needed to produce a bad state. Subsequently, SMT solvers are used to check if there is any real input that can satisfy the bad condition. Really cool tech, but unfortunately it cannot be fully automated, and it often struggles with loops with and interprocedural analysis.
- Model Checking: This approach somewhat ditches value and control flow analysis by “writing down” all concrete executions, and then using SMT solvers to determine which executions are feasible. Its advantage is ultimate bit precision, but as you might imagine, it is very costly in terms of analysis time. Also, it struggles with loops even more than with pointers: If you have a loop with 100 iterations, it must model all steps within the loop 100 times. That’s an exponential complexity explosion. And if you feel cheeky and create a loop with a dynamically calculated bound, it is completely lost without further tricks.
That’s it for this post. It may not be very scientific, but I hope it has helped you to understand what happens behind the scenes, and how you can get better results from your Static Analysis tool.
What’s next?
If all goes well, the next article will be about Static vs. Dynamic Analysis. Let’s talk about what Memory Safety is, and how Static Analysis makes it safer.