Memory safety is often tragically misunderstood. Claims like “it eliminates all memory errors” are at best misleading, and can be a recipe for disaster. In this article, I will explain what it really means, where it has limits, and why Static Analysis is the best way to eliminate memory errors.
This post is a bit beyond the usual topics. But it is important, and I want to help developers to see through the current hype that is memory safety. Now before you think I am against it and the new languages around it, let me start with a disclaimer:
- Memory safety is great, it avoids many bad consequences!
- I use and like memory-safe programming languages like SPARK and Rust!
But if you think memory-safe programming languages solve the problem of memory errors, you are in for a surprise.
What is Memory Safety, and why bother?
First, why should we even bother about memory errors? Simple – because they are our toughest software nemesis for ages. We all know the infamous segmentation fault, or off-by-one errors with arrays. They can be tough to debug, and cause a lot of headache. Studies in the big software projects like AndroidTM and iOSTM show, that memory-errors are the most frequent type of error [1][2][3]. Researchers have also acknowledged this [4][5] and MITRE’s top list of vulnerabilities always contains memory-related errors. Thus, getting rid of memory errors would be an epic achievement.
Enter Memory Safety, a promise that goes in the right direction. According to Wikipedia:
“Memory-safety is the state of being protected from various software bugs and security vulnerabilities when dealing with memory access […]”
Further down the Wiki page, we even get a list of examples that may resonate:
- Access errors:
- Race conditions,
- unwanted aliasing,
- over-read or under-read of buffers.
- Initialization errors:
- use of values and pointers which have not been initialized.
- Resource management errors:
- invalid or mismatched free,
- heap or stack exhaustion.
This gives us a good understanding of what memory safety wants to achieve. If you insist on a more precise definition, take a look at this academic article (but be warned, this is surprisingly difficult).
The urge and the misleading simple solution
Recently, many people claim that we can reach memory safety by merely choosing the right programming language. And that includes clever people from CISA and the White House, who insist that memory-safe programming languages must be used by 2026 or else…see here.
However, this promise of memory safety is too good to be true. It is an oversimplification, perhaps because we humans like simple solutions. Here I am, talking about the nasty details, saying that changing the language does not solve the problem. And I am not alone – the MISRA committee agrees on that, too. Let’s understand why…
The two fundamental ways to reach Memory Safety: Prevent or Detect
We can either prevent memory errors by eliminating all root causes, or we can detect them when they happen. Both approaches are valid, as long as we don’t actually let the bad memory access play out. To thoroughly understand the difference between detection and prevention, let’s look at this with a daily example:
Example: You want to avoid the flu
You want to avoid suffering from the seasonal influenza virus. You are doing detection if you start feeling unwell and go to see a doctor. She will give you a sick certificate, and maybe some meds to lessen the symptoms. You still suffer some consequences, but it is much better than ignoring it and risking more serious health problems.
In contrast, you are doing prevention if you get vaccinated. Ideally, you will never get sick, and hence you have zero consequences. Sounds better.
But – as some of you might be objecting right now – prevention also has a price, and it may not be a 100% effective, either. Correct. Each of the both approaches has different cost, effectiveness and different consequences. Now let’s to see how that applies to memory safety.
Memory Safety through Detection – an incomplete solution!
Detection means that we don’t try to prevent the root causes for memory errors. Instead, we only try to catch them when they happen. Most memory-safe languages guarantee memory safety this way. They check each memory access during run-time, and refuse executing it when something is wrong. Alternatively, we can use hardware to do (some of) these checks, which is how the operating system produces these lovely segfaults.
An example in Rust can be see below (how did this even compile?):
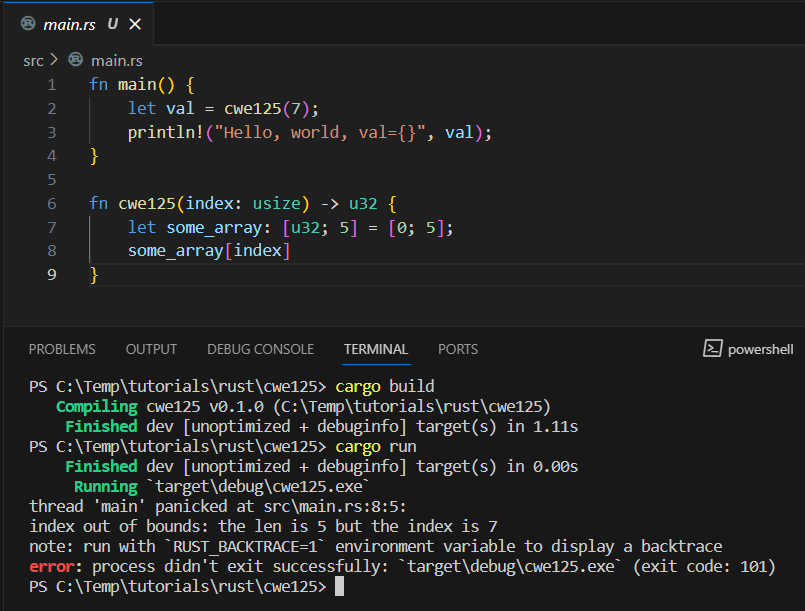
In this simple program, I have created an array of length 5. Then, I am trying to access the 7th element through a function call. Of course, this can’t work. We can see that the program compiles which means that the language itself does not prevent this. It also means that the compiler was not able to predict this error. Only during execution, the memory error is detected and stopped by a panic, which is somewhat like an exception that cannot be handled.
It is debatable whether the compiler should have detected this specific pattern. Exhaustive compile-time checks could take a long time, but we all want our compilers to be fast. Therefore, it is a valid approach to do some checks during run-time.
Memory safety is often achieved by terminating the program when memory access goes wild.
Detection is not enough
The problem is, that we still get into that bad situation, where the program terminates. But is it a good solution to just stop the program? I had many discussions on that, and one frequent answer was:
“This panic works as intended, that’s not a memory error! It’s like a controlled emergency landing of an airplane.”
Yes, we could argue that a controlled program termination works as intended. This is acceptable for a web server, or for the Desktop software we use to analyze data. But hopefully that software isn’t anything critical like a flight controller. Or the pacemaker protecting the life of your loved one. In that case, good luck explaining this to your boss, or the assessor who certifies your flight control software.

I hope we can agree, regardless of what type of software you are writing, that an exception or panic is typically not intended. Typically, it is a rather unwelcome surprise, and we should correct it. It will certainly make you uncomfortable, especially if you would ironically sit in that very plane doing an emergency landing.
Note that in some situations (C++ or Java exceptions) the developer can actually handle the detected error, but in others she cannot (Rust panics or segfaults). But even if she can, did she really do it? How many exceptions have you not handled? Me – too many. As as we know from an earlier post, that’s just human.
Detection is still very useful!
Okay, so our program crashes to protect us from memory errors. Why are people so hyped about memory safety? Because this is still useful. Errors are detected reliably, and the consequences are limited.
Let’s say there is an attacker who sends some weird inputs to your software and causes a memory error. If the attacker is really skilled and lucky, he can exploit this situation to change the program behavior, or even inject his own code. This could, for example, turn your engine controller into a toaster.
Example: To illustrate this, let’s look at the following C program. I am sending some well-crafted inputs that overwrite a variable A that is supposed to be constant:
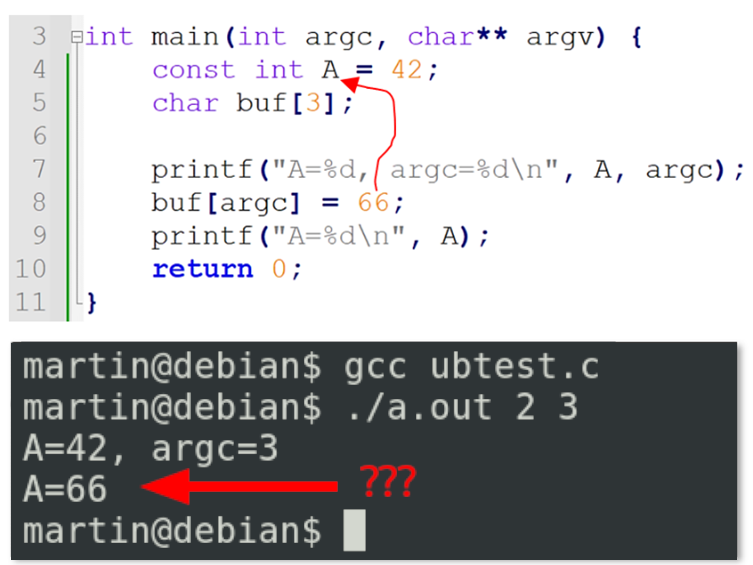
What happened here? Obviously, this is completely against the language semantics. Well, here we have a common memory error known as “buffer overflow”. In line 6, we write into a buffer at a position defined by the input argc. My input is argc=3, so we write at the 4th position (in the C language, we start counting at zero). But the buffer is only 3 elements long, which means we write outside of the buffer. And as it happens, the variable stored next to the buffer in memory is … A. Thus, we are silently and unexpectedly writing into A, instead of buf, changing its constant value. In the world of C programming, this is called Undefined Behavior and may have various effects (and produce a toaster, indeed).
This cannot happen with memory-safe languages like Rust, since the controlled termination prevents such abuse. Hence, the attacker cannot do much except crashing the program. As we can see, detection of memory errors reduces the consequences. It also helps finding memory errors reliably during testing or operation. So yes, we should be happy about it, but we can do better.
Memory Safety through Prevention – the way to go!
The best way to achieve memory safety, is to write our software so that we never get into a situation that would require an exception or a panic. Then we would have zero consequences. This is easier said than done (apart for that one colleague whom we all know, who makes no mistakes). But, luckily, we actually have several methods that can help to truly prevent the root causes of memory errors:
- Language that prevents memory errors: We could use a strict language that does not permit even attempting any abnormal operation. In practice, this is not really possible, since it would be a very inflexible language (e.g., one without pointers). But many languages can prevent at least some memory errors. For example, Rust can prevent dangling pointers due to its ownership paradigm, but it cannot prevent out-of-bounds accesses as we have seen.
- Use safe(r) language subset: Some language constructs are safer than others and should be preferred. Looking back at the Rust example, I should have used the Result enum. In that case, no panic could have occurred, because I would have been forced to handle the out-of-bounds case explicitly. Coding guidelines, like the famous MISRA C and CERT C guidelines, have been created exactly for this purpose. Not surprisingly, many safety and security standards strongly recommend this approach, which is typically achieved with – you guessed it – static code analysis tools.
- Model-based design: This may be seen as a crossover of the two former points. Instead of writing code, engineers application design their application in a graphical framework. This provides blocks can be put together like Lego. Then, the model is automatically translated to source code. The modeling “language” already forbids certain constructs and does not (fully) expose a memory model to the user, thereby preventing many memory errors. The translated code typically only uses safe language constructs, further reducing errors.
- Formal verification: We can use mathematical methods to identify memory errors thoroughly, before we run the program. It works somewhat like static code analysis, but the underlying “analysis engine” is more sophisticated. It is a special type of static analysis. If implemented and used correctly, it can not only detect many error classes reliably, but moreover, even prove their absence. This sounds like rocket science, but is nothing to fear. We will cover this in a later article.
As a side note, compilers are also clever and can identify some errors. However, they need to be fast, and therefore they are only discovering more shallow errors. See above.
It’s better to prevent the root causes of memory errors, to avoid hidden surprises like run-time panics.
You should see Memory Safety as a spectrum (which includes C++)
There is one more insight that we can draw from the flu-analogy: Neither detection nor prevention need to work 100% reliably. The doctor might misdiagnose you, the meds might not work, or your vaccination might not protect you from the latest variant of the flu, or it might only work for a limited time. In analogy, we should not see memory safety as a Boolean property (or as a “state”, as Wikipedia puts it). Our methods may only have partial guarantees.
If we allow memory safety to have shades of grey (from “not safe at all” to “100% guaranteed”), we can see that even programming languages like C++, often oversimplified as “unsafe” – do have features that are memory-safe. For example, std::array::at() checks array access and throws an exception when you try to go out of bounds. And that means that C++ has been attacked too harshly by the CISA, NSA and others.
The caveat, just like in our analogy, is that prevention only works when you use the safety features of a language. Ideally, they should be “on by default”. The C++ committee has acknowledged this, and is currently working on “safety profile”.
The true Roadmap to Memory Safety
Since no programming language can fully solve the problem, what is the best solution then? How can we answer to authorities like CISA, who demand a roadmap to memory safety, in particular for “unsafe languages”?
Always combine multiple approaches!
For new software, you should definitely choose a memory-safe programming language. You can prevent some errors with the stricter language rules. With run-time detection, you can reliably find errors when they occur. This avoids bigger problems like missed defects or remote code injection.
Crucially, make sure that you also use Static Code Analysis and coding guidelines for “safe” languages. We have seen one example above. This reduces the number of critical operations and failing run-time checks. If you need more convincing that you need guidelines for Rust, have a look at the free publication “Applicability of MISRA C:2025 to the Rust Programming Language” from the MISRA Consortium. That document shows clearly how many of the well-tested MISRA guidelines are not addressed by the Rust language itself, and hence that guidelines and static code analysis are not a bad idea.
Static Analysis is an essential tool to achieve memory safety, regardless of your programming language.
For legacy software, you also should use static code analysis (does that really surprise you?). Moreover, you can use compiler extensions like the clang sanitizers, to enable run-time detection of memory errors in C++ programs.
The best option to truly prevent the root causes of memory errors, are Formal Methods. They can mathematically prove the absence of certain memory errors, and thus point to all the places in your code that could lead to run-time errors. If you systematically fix all these locations, this ensures that your software behaves as expected, under all possible conditions, and that there are no hidden surprises.
Because in the end, you want to prevent, not just detect.
What’s next?
In the next post, we will understand the differences between Static and Dynamic Analysis.